Modern GPUs are capable of vastly reducing training times on neural networks. However current solutions are not exactly out of the box. This means that a lot of folk who are new to machine learning are not sure how to get this set up. In this article I will consider one particular approach, using TensorFlow with CUDA in a Python environment. If you are already sold on the idea of TensorFlow on GPU you can skip to my install guide. If not, read on
Firstly do you need GPU enhanced TensorFlow? Your thought process should go something like this:
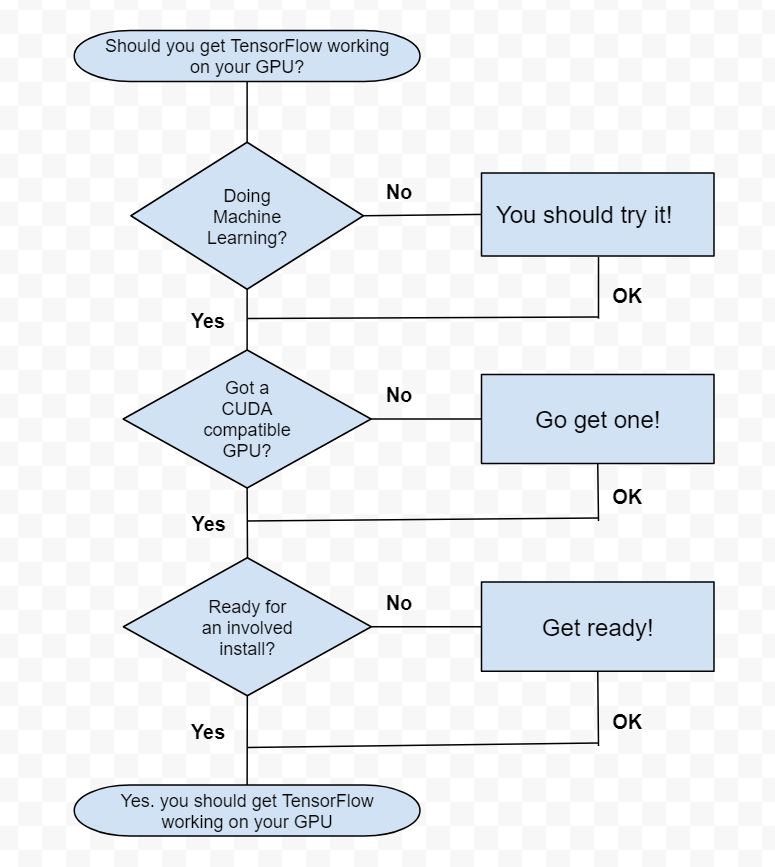
Running TensorFlow on a decent GPU can be expected speed up your machine learning calculation times enormously. Lets look at a comparison on a training epoch from my LEGO recogniser using the same training data run on CPU and GPU
Here are the CPU timings on an Intel i5

And here are the GPU timings on a GeForce 1080

Look at the figures outlined in red. That is approximately an 6 times speed up without any code optimisation. All that has changed is using TensorFlow for GPU with CUDA rather than on the CPU. Its also worth noting that while the i5 was maxed at 97% on the CPU run, the 1080 was nowhere near capacity on the GPU run, the main bottleneck was piping the data to and from the graphics card.
Now lets try actually changing the batch size, with a little experimentation we can get:

Yes you read that right, that is a 100 times speedup on the training by using TensorFlow for GPU!
The install process to get this up and running is a little involved and can take a couple of hours, however if you are training a lot of models the time investment should pay itself back quickly. I have detailed my install experience as a handy guide to help you get up and running.