One change you may find with GPU acceleration is that you may wish to change some hyperparameters when training models. One of the key ones to consider altering is batch size. Basically we will get the fastest training if we set the batch size of images to process simultaneously as high as possible. for instance in the LEGO image recognition challenge we can increase the batch size from 16.
Replacing
# batch size used by flow_from_directory and predict_generator batch_size = 16
with
# batch size used by flow_from_directory and predict_generator batch_size = 128
speeds execution from 2.46 seconds to 0.12 seconds, a 20 fold improvement which indicates that most of the bottleneck in performance is moving data on and off the GPU. Eventually increasing batch size will give you an error along the lines of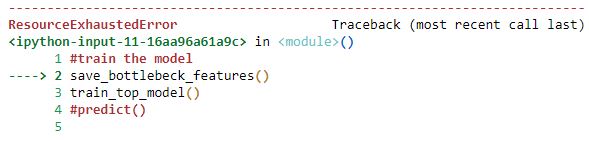
This indicates that you exceeded the available memory during processing and will need a smaller batch size. For my LEGO project this occurred at a batch size of 256, obviously the complexity of your network and size of items in your data batch will affect this dramatically.
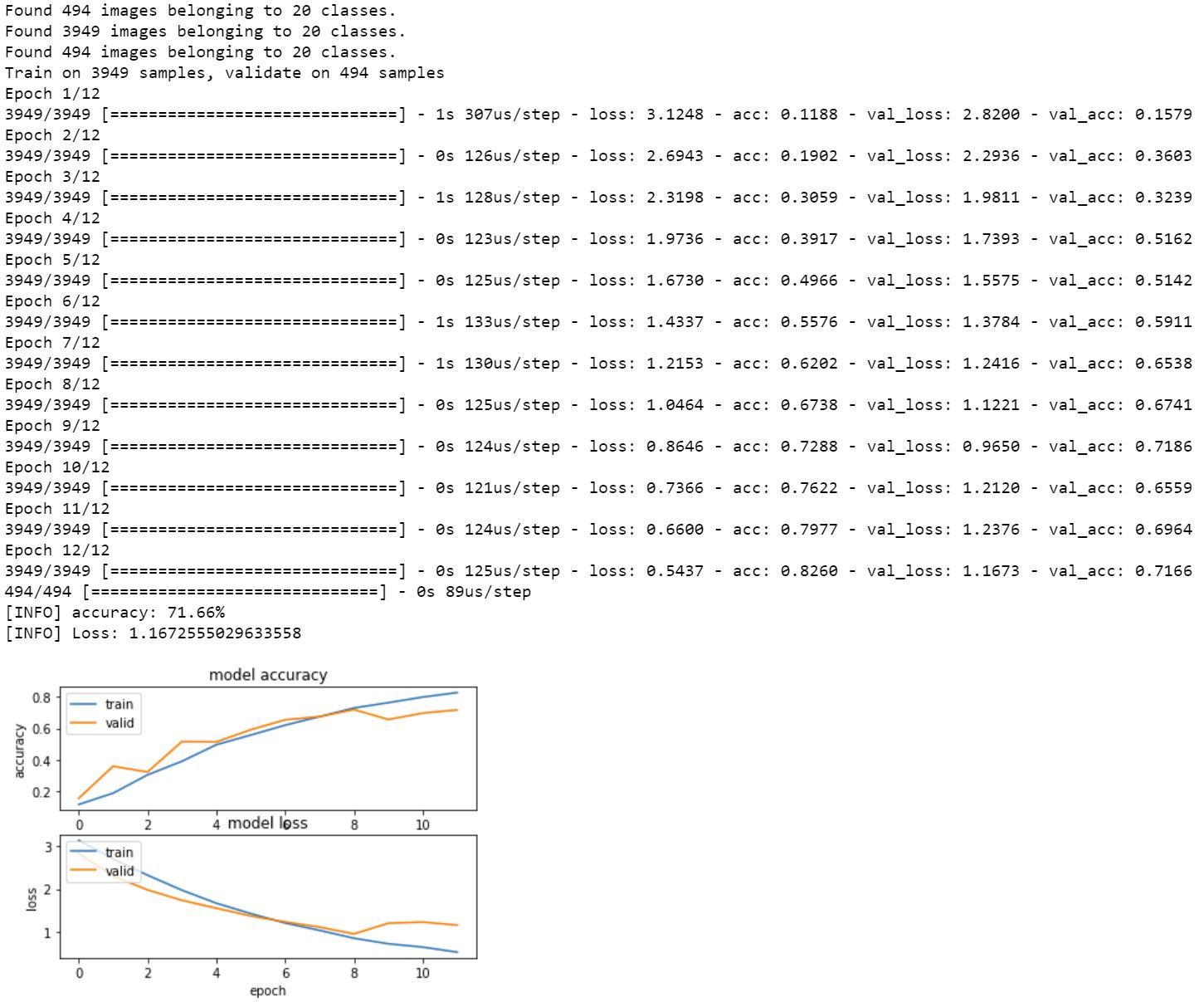
Another thing to consider is that when you are changing your batch size you are effectively altering one of your model’s hyperparameters. This can have knock on effects on how many epochs it takes for your model to converge. Rerunning the model for 20 epochs at batch size 128 gives the following loss graph
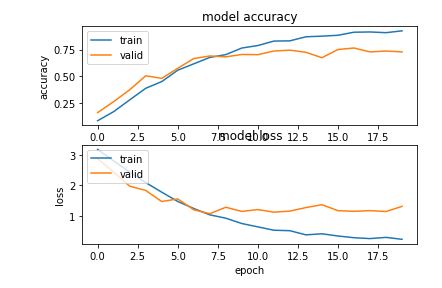
this suggests that we should extend the early stopping for our training from 6 epochs to 8 or even 12. Stopping after 12 epochs gives us better validation set accuracy (72%) and better validation set lower loss (1.17) than our original CPU runs ( accuracy of 66% and loss of 1.22) in a mere fraction of the time as seen below