Pyspark is very powerful. However because it is based on Scala we need to be careful about types as they are not Pythonic. And because it follows some SQL conventions we need to be aware of casing issues. Here are a few examples of gotchas to be aware of.
Beware when Combining PySpark ‘null’ with Logical Operations
Nulls in columns don’t just fail equality tests, they also fail the inverse of the same equality tests and so you can have an excluded middle issue where some rows in your dataframe can be excluded both from a logical operation and from its inverse. See the picture below for a simple example .

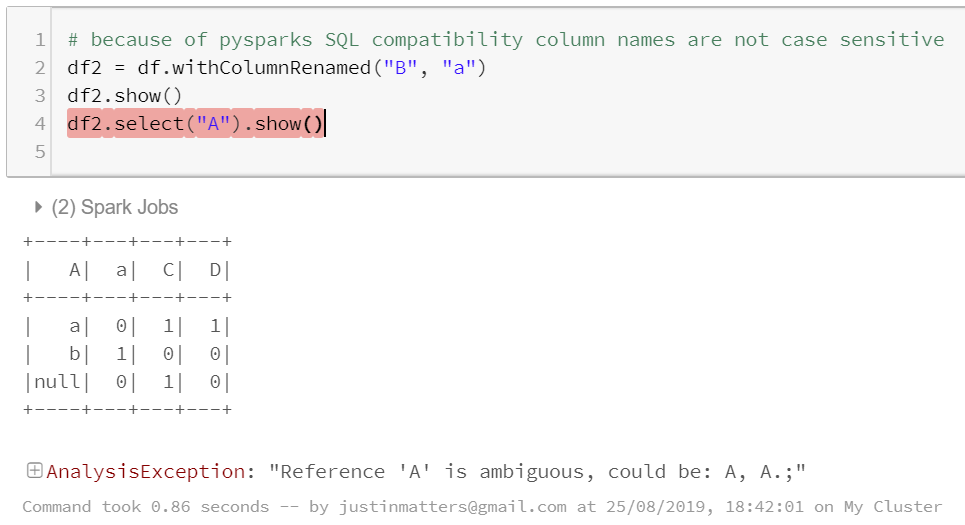
PySpark Column Names are not Case Sensitive
In common with SQL, PySpark does not have case sensitive column names. However it does not alert when you rename a column in such a way that it clashes with an existing column. What it will do is throw an error when you try to select the now duplicated column name. This should not normally be an issue, but be careful when converting from pandas dataframes or importing data.
PySpark’s Types are not Python Types
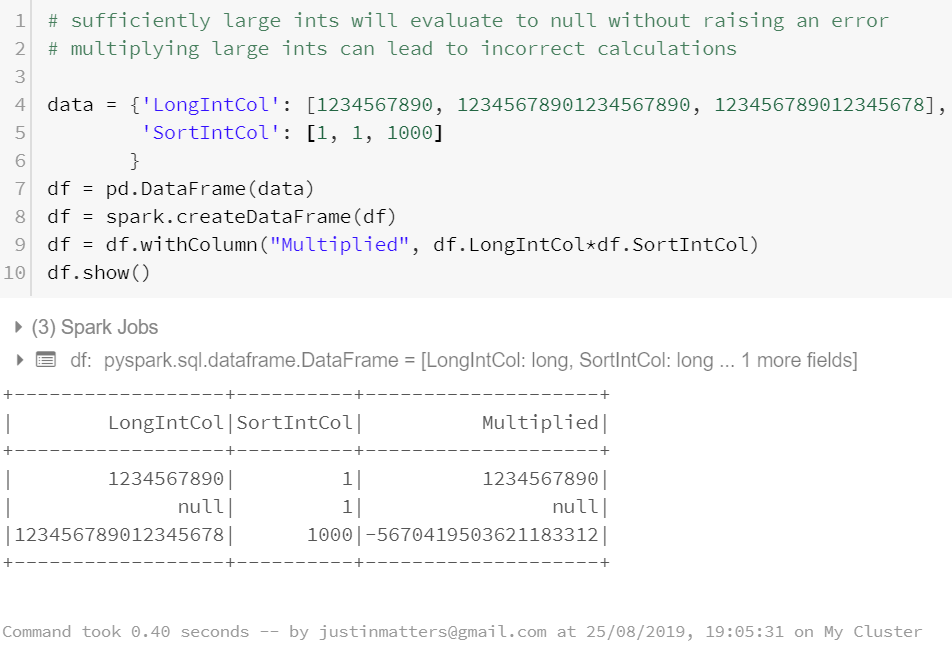
PySpark’s types are not Python types. This seems obvious but it can lead to unusual or unexpected behaviour. Firstly PySpark has permissive typing. If you attempt to perform mathematical operations on a mixture of strings and integers and the strings can convert to integers this will occur without raising exceptions. More dangerously this will happen even if only a subset of the rows can be handled in this way.

Also PySpark integers are not python integers. There are two types, short int and long int and overflowing them results in null values. This can be partially overcome by use of floats at the cost of loss of precision.
PySpark Cannot see Hidden Files
Files which start with _ and . are hidden files. This means that operations which try to load files starting with these characters will fail. The easiest solution here is simply to rename the files.
If you have an account on Databricks Community Edition you should be able to see the examples covered here in a shared workbook here:
https://community.cloud.databricks.com/login.html#notebook/1193701472353038/command/1193701472353039